
Having spent years in the trenches of data engineering and enterprise platform management, I’ve had a front-row seat to one of the most blindingly fast evolutions in technology: how organizations manage, store, and extract value from their data.
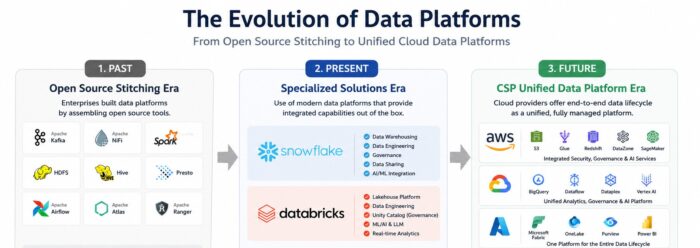
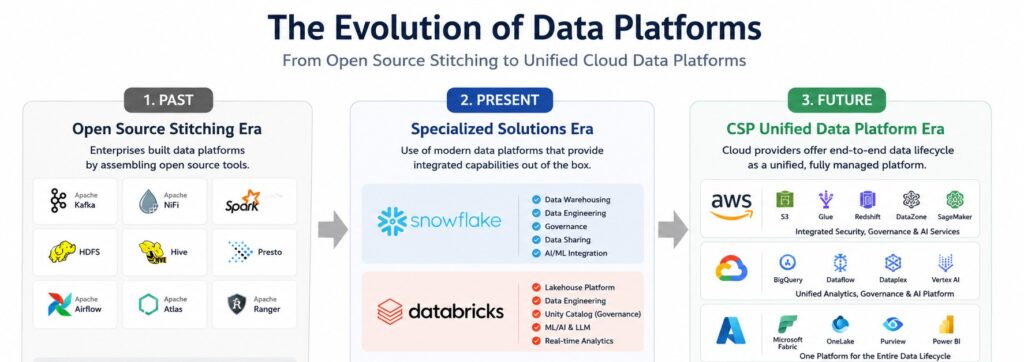
Not too long ago, building a big data platform meant hiring an army of specialized engineers to manually stitch together a brittle web of open-source frameworks. Today, we are firmly in the era of specialized turnkey cloud solutions like Snowflake and Databricks. But the horizon is shifting again. We are rapidly moving toward a future where Cloud Service Providers (CSPs) like AWS, Google Cloud Platform (GCP), and Microsoft Azure absorb the entire data lifecycle into unified, highly integrated ecosystems.
The modern data market can be summarized in one overarching trend: the convergence of data engineering, data governance, AI/Agents, and operational automation into a single cohesive framework. Data platforms have transformed into the active operational nervous system required to power real-time generative AI and autonomous agents.
Let’s dive deep into the three distinct stages of this evolution, analyze the massive paradigms shifts redefining the industry, and explore what this means for the future of data engineering and organizational strategy.
1. The 3-Stage Evolution of Data Platforms
The journey of the modern enterprise data stack can be broken down into three major tectonic shifts.
Stage 1: The Open-Source Assembly Era
In the early days of big data, commercial enterprise-grade end-to-end platforms simply did not exist. To unlock the value of massive datasets, data engineers had to handcraft pipelines by manually wiring together disparate open-source tools.
An architecture from this era typically looked like a complex pipeline of individual components:
- Ingestion & Orchestration: Tools such as Sqoop were used to import data from relational databases, while Kafka handled real-time streaming data pipelines. NiFi and Airflow were commonly adopted to schedule, orchestrate, and manage complex workflows across the data pipeline.
- Processing & Computation: Spark and Flink served as the primary distributed computing engines. These technologies enabled to process massive volumes of batch and streaming data efficiently across clustered environments.
- Storage & Querying: Petabytes of raw data were stored in the Hadoop Distributed File System (HDFS) or cloud object storage systems. Hive was often used to organize and structure the data into table-like formats, while distributed SQL query engines such as Presto and Trino allowed analysts and engineers to perform high-speed interactive analytics on large-scale datasets.
- Governance & Security: Organizations relied on dbt to manage data transformation workflows and modeling practices. Atlas was used for metadata management, data cataloging, and lineage tracking, while Ranger provided fine-grained access control and centralized security policy management across the data platform.
While this custom-built approach allowed organizations to tailor systems to their precise performance requirements, the infrastructure overhead was crushing.
Stage 2: The Turnkey Specialized Solution Era
Companies like Snowflake and Databricks radically altered the landscape by introducing a breakthrough architecture: the absolute decoupling of storage and compute. By separating these two layers, businesses could store virtually unlimited amounts of data cheaply in cloud object storage and scale massive compute clusters up or down in seconds, paying only for the exact seconds those compute resources ran.
Stage 2 introduced the concept of the unified turnkey platform:
- Integrated Governance: Instead of trying to maintain separate tools for tracking lineages and access controls, features like Databricks Unity Catalog emerged. Unity Catalog provides a single, unified governance layer for data lineage, security, and quality across files, tables, and AI models within a single pane of glass.
- Convergence of Data & AI: These platforms quickly evolved past standard SQL queries. They began embedding AI/ML feature stores, vector search indexes, and dedicated Large Language Model (LLM) serving capabilities natively into their environments.
Stage 3: The Unified Cloud Native Data Fabric Era
We are currently in the midst of the third stage, characterized by the hyper-integration of data lifecycles by the “Big Three” cloud service providers: Microsoft Azure, Google Cloud Platform (GCP), and Amazon Web Services (AWS). Rather than purchasing separate third-party SaaS solutions and figuring out how to connect them, enterprises are leveraging cloud-native Data Fabrics where ingestion, processing, analytics, governance, and AI are natively interwoven into the underlying infrastructure.
Microsoft Fabric is one of the most aggressive examples of this strategy. Microsoft has fully unified Data Factory (ETL), Synapse Analytics (big data analytics), Power BI (visualization), and Purview (data governance and quality management) on top of a single logical storage layer called OneLake. As a result, users can manage everything from data ingestion and governance to analytics and business consumption within a single SaaS-like environment.
GCP is pursuing a similar strategy centered around BigQuery, which has evolved far beyond a traditional data warehouse into a large-scale unified data platform. Through Dataplex, Google automates data governance, metadata management, and data quality controls across the cloud environment. Processed data can then flow directly into Vertex AI — without unnecessary data duplication — enabling seamless integration with LLM training and generative AI workloads.
AWS is also accelerating its “Zero-ETL” strategy, which aims to minimize data movement across systems. For example, data generated in Amazon Aurora can now be synchronized in real time with Redshift or OpenSearch without building separate ETL pipelines. In addition, AWS DataZone provides integrated capabilities for business-oriented data cataloging, data quality management, and secure data sharing across organizations.
2. Critical Paradigm Shifts and Strategic Insights
Here are the four key paradigm shifts that organizations must navigate:
Shift 1: Shifting the Focus of Data Engineering: From Infrastructure to Data and AI
In the past, data engineers had to spend most of their working hours on “infrastructure management (DataOps)”—painstakingly tuning Hadoop clusters, patching broken pipelines, and resolving open-source version conflicts.
However, as integrated cloud solutions handle infrastructure management automatically through serverless and fully managed architectures, engineers can finally shift their focus from the underlying infrastructure to the data itself. In other words, core competitiveness has pivoted toward implementing business logic and creating intrinsic data value. This involves answering critical questions such as, “How can we make enterprise structured and unstructured data more machine-readable for AI (AI-Friendly Data)?” and “How can we maximize the quality of our data supply chain (Data SCM)?”
Shift 2: The Convergence of Data Governance and AI Governance
Traditionally, data quality management was limited to simple tasks like checking for missing values or verifying format consistency. However, with Generative AI now positioned at the final stage of the data lifecycle, the entire concept of governance has fundamentally changed.
Today, meticulous quality control during the data collection and processing stages directly impacts AI performance optimization and risk mitigation (such as preventing hallucinations, data leaks, and algorithmic bias). Consequently, organizations must proactively build frameworks utilizing integrated governance tools provided by Cloud Service Providers (CSPs). This allows them to track the entire lifecycle through end-to-end lineage tracking on a single pipeline—all the way from the data’s origin to AI model training and deployment.
Shift 3: AI and Agents Moving Inside the Data Platform
Snowflake and Databricks have evolved far beyond mere data repositories. Today, they natively embed high-performance SQL engines alongside vector search capabilities, AI inference, and LLM orchestration tools directly within their platforms.
As a result, the boundary between “data platforms” and “AI platforms” is completely vanishing. We have entered an era where developers can run AI models and build applications right where the data lives, eliminating the need to move data to external environments.
Shift 4: The Dilemma of Multi-Cloud Strategies and Vendor Lock-in
While the integrated solutions offered by cloud infrastructure providers are incredibly convenient, they carry the risk of severe vendor lock-in within a specific cloud ecosystem.
Organizations must now thoughtfully address strategic data architecture governance. They need to decide whether to standardize a single cloud provider’s integrated solution as the enterprise standard, or build a skeletal framework using solution-centric, multi-cloud flexible platforms like Databricks or Snowflake, and then snap in specialized features from various clouds like Lego blocks.
Conclusion
Moving forward, data platforms will evolve beyond simple storage and processing systems into “Agentic Data Platforms” driven by AI-powered automation.
Accordingly, we anticipate a massive shift in the roles and core competencies required of data engineers. While their primary role up until now has been combining various open-source tools to keep platforms running stably, tomorrow’s engineers must become “AI-Driven Data Operations Architects.” In this role, they will leverage AI intelligence on top of unified platforms to design the overarching data flow and business value. Now is the time to accurately read the trends of this changing platform ecosystem and devise a data strategy tailored to your organization. value has officially arrived.