
If you’ve been watching the tech world lately, you might have noticed a massive shift in how the biggest names in artificial intelligence are hiring. Giants like OpenAI, Anthropic, and Google are no longer just bidding over pure research scientists. Instead, they are locked in a fierce, high-stakes talent war for a very specific role: Forward Deployed Engineers (FDEs).
Historically, the concept of the FDE was pioneered by Palantir in the early 2010s to bridge the massive gap between raw software capabilities and complex, real-world customer operations. Today, that playbook has gone completely mainstream across the entire AI ecosystem. Google Cloud’s CEO Thomas Kurian recently announced plans to hire hundreds of FDEs to scale corporate transformation, while OpenAI launched its dedicated “OpenAI Deployment Company” explicitly to embed these engineers into complex enterprise environments.
But why this sudden, aggressive push? It is difficult to build, deploy, and operate production-grade AI systems in real enterprise environments. Up until now, the jaw-dropping AI use cases making headlines were largely built in highly controlled sandboxes, leveraging near-perfect, idealized datasets to perform narrow tasks. But when you try to drop those same models into the tangled web of a real-world enterprise, they stumble. They have to roll up their sleeves, embed engineers directly into the client’s workplace, and fix the messy structural foundations underneath. And at the absolute core of that structural mess is one thing: Corporate Data.
AI Agent Development Journey
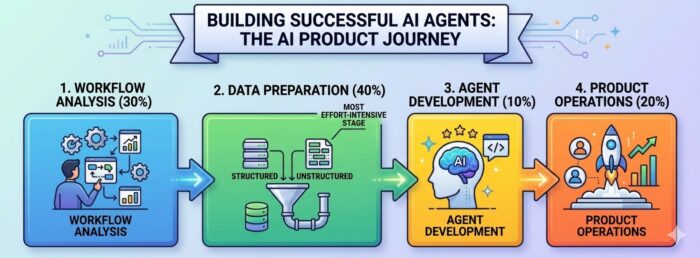
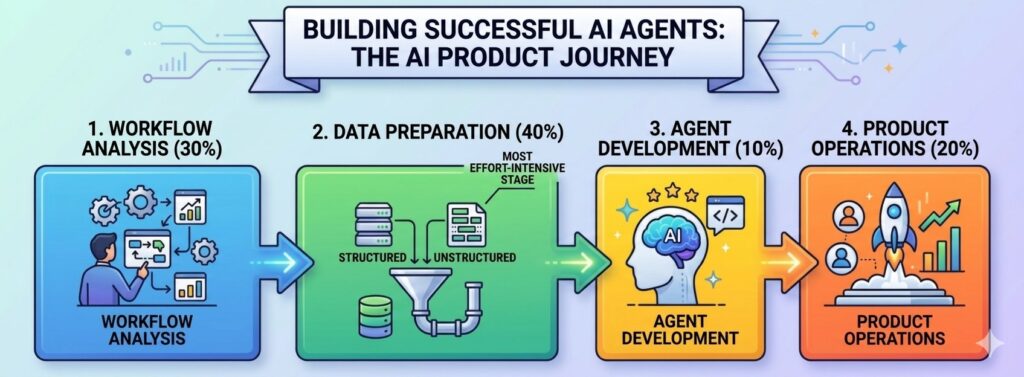
When we talk about deploying an enterprise-grade autonomous AI Agent, the journey involves a distinct four-stage pipeline. Many executives and software leaders mistakenly assume that writing the code or training the actual AI model consumes the lion’s share of the timeline.
In reality, the distribution of effort is heavily lopsided. Based on hands-on implementation experiences across complex corporate architectures, the required effort typically looks like this:
- Workflow Analysis and Mapping: 30% of total effort
- Data Preparation and Integration: 40% of total effort – The Ultimate Bottleneck
- Agent Development and Prompt Engineering: 10% of total effort
- Product Operations and Productionization: 20% of total effort
To understand why building an AI Agent is actually a data-first problem rather than a coding problem, we need to take a closer look at what actually happens inside each of these distinct phases.
1. Workflow Analysis (30%)
Before an AI Agent can automate a business function, it must understand the rules of the game. This stage is absolutely vital for defining the AI’s core objectives and measuring its ultimate ROI. The challenge? Most enterprise workflows do not live in clean, updated documentation. Instead, they exist as tacit knowledge—undocumented institutional habits locked inside the heads of veteran employees. Explicitly parsing, aligning, and translating these organic, fragmented processes into a structured roadmap that an AI can follow takes an enormous amount of cross-departmental alignment and structural mapping.
2. Data Preparation and Integration (40%)
This is the most grueling, energy-sapping, and critical phase of any machine learning or agentic initiative. It spans everything from finding where the necessary data is hidden across departmental silos, extracting it, building resilient data pipelines, cleaning up anomalies, and ensuring strict enterprise-grade data security and compliance. This phase alone routinely devours nearly half of the entire project’s energy because it represents the raw operational fitness of the enterprise itself.
3. Agent Development (10%)
Thanks to the astonishing pace of innovation from frontier model providers and open-source ecosystems, this has unexpectedly become the easiest slice of the pie. With sophisticated developer frameworks (like LangChain, LlamaIndex, or native agentic SDKs) and highly capable foundational LLMs, assembling the actual digital brain of the agent can be executed remarkably fast. Because you can rapidly plug into external tools and pre-built orchestrators, the core development phase demands the least amount of relative effort.
4. Product Operations (20%)
A shocking number of corporate AI projects get trapped in a perpetual loop of “Proof of Concept” (PoC) purgatory. Transitioning an experimental chatbot into a rugged, reliable enterprise product that actively supports executive decision-making or executes automated operational actions requires extensive product management. You have to design robust fail-safes, real-time monitoring infrastructure, continuous feedback loops, and user-friendly interfaces so that the business can trust the AI with live operational dependencies.
Why Now is the “Time of Data” for Agentic AI
If your data is fundamentally flawed, an autonomous agent won’t just generate a bad paragraph of text; it will execute an incorrect operational action. Let’s look closely at the core reasons why data preparation and integration represent the definitive battleground for enterprise AI success:
The Absence of Data Governance and the System Fragmentation
- The Internal Discovery Barrier: You cannot feed an AI Agent data that you don’t even know exists. In most large corporations, data is hopelessly fractured across legacy mainframes, disconnected cloud instances, and localized databases managed by entirely different business units.
- The Governance Deficit: A recent Gartner CDAO survey revealed a startling reality: only 13% of data leaders report that their existing data governance functions are mature enough to fully lead AI governance (Source: Gartner Data & Analytics Survey). Without a unified data governance framework, simply verifying data lineage, ensuring access rights, and gathering inputs turns into an administrative and logistical nightmare that drains momentum before the first line of AI code is even written.
The “AI-Friendly Data” and Metadata
- The Context Gap: Corporate data is a chaotic mix of structured tables (SQL databases, ERP systems) and massive oceans of unstructured assets (PDFs, internal wikis, engineering blueprints, emails). To build a reliable agent, this unstructured data must be carefully extracted, cleaned, and heavily enriched so that an AI can comprehend its structural boundaries.
- The Fallacy of Human Readability: Just because a human being can easily look at a document and understand it, does not mean an AI can.
- Active Metadata Practices: This is where comprehensive metadata management becomes non-negotiable. AI models require highly granular meta-tags, semantic anchors, and structural annotations to accurately process files without hallucinating.
Connecting the Data in Exact Context
- The Fluidity of Meaning: In a corporate environment, a single data point can mean totally different things depending on the situation. For instance, the phrase “delivery date” means one thing to a factory-floor supply chain manager, another thing to an account executive dealing with client billing, and something entirely different to a service manager.
- Typifying Tacit Knowledge: Connecting raw data to the precise business context is essentially the process of taking organic, real-world human expertise and mapping it into a digital data graph. This cannot be done by pure data engineers working in isolation; it requires an intimate, deep-dive understanding of both the overarching operational workflows and the underlying data schema simultaneously.
The Continuous Data Maintenance
- If you standardize your methodologies, mapping workflows eventually becomes repeatable. If you set up an integrated development environment, writing agent prompts and deploying software can be streamlined. Product operations can eventually be centralized into a single dashboard.
- However, because corporate data expands dynamically every single minute—fluctuating wildly in quality, format, and accuracy across different business domains—it demands continuous, active oversight. Data preparation isn’t a milestone you cross off a list; it is a permanent, foundational loop.
Conclusion
As we venture deeper into this exciting era of autonomous AI Agents, the ultimate competitive differentiator for any enterprise will not be the specific foundational model they choose to plug into. Models are rapidly becoming democratized commodities; anyone can rent access to the world’s most sophisticated digital brains for pennies on the dollar.
The real winners of the AI revolution will be the companies that possess the cleanest, most securely governed, and most contextually connected internal data architectures. If your underlying data is disorganized, noisy, and fractured, even a multi-billion-dollar frontier model will generate useless, hallucinated actions. But if your data is meticulously prepared, pristine, and perfectly mapped to your operational realities, your AI Agents will run flawlessly, driving massive bottom-line value.
The flashy, headline-grabbing technology might be the AI Agent, but the beating heart that keeps it alive is your data ecosystem. It is time to focus on building your data foundation. It is officially the time of data.