
Introduction
In the rapidly expanding world of artificial intelligence (AI), most organizations no longer attempt to build models from scratch. Instead, they adopt pre-trained foundation models — such as large language models (LLMs) or vision models — developed by global tech leaders like Google, Meta, Microsoft, and OpenAI. These foundation models require enormous datasets and computational resources that most organizations simply don’t have. After adopting them, many enterprises fine-tune or post-train these models with their own data to tailor performance to specific internal business needs.
However, the single most important factor that determines success — more so than the choice of model architecture — is how the data used to train, validate, test, and operate the model is managed. Even with the same model, the quality and robustness of data management can dramatically influence accuracy, trustworthiness, and stability. In this article, we explore practical strategies for managing AI data — from splitting datasets to version control — to ensure effective, scalable AI model development.
Understanding the Types of Data in AI Development
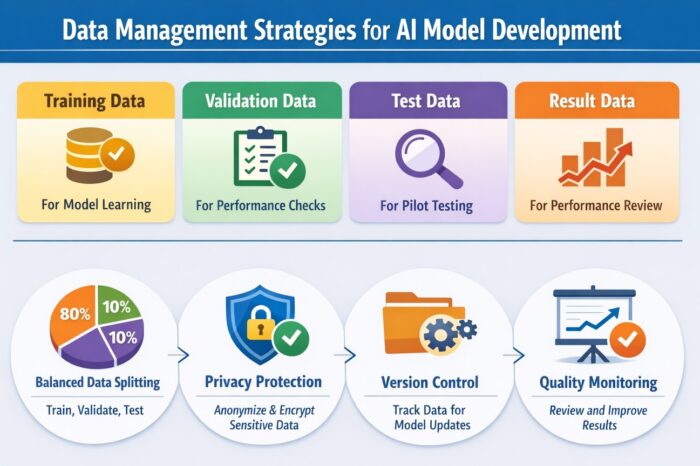
AI models use several distinct types of data throughout their lifecycle. Knowing how to categorize and manage these types is foundational:
1. Training Data
Training data is the core dataset that teaches your model how to recognize patterns. The more relevant and diverse this set is, the better the model can generalize to new inputs. In practice, training datasets often account for 60–80% of the total dataset and must include a balanced representation of all expected real-world scenarios. Without representativeness, models can produce biased or unreliable results.
2. Validation Data
During model development, validation data helps monitor how well the model is learning. It acts as a checkpoint for tuning hyperparameters (training settings) and detecting issues like overfitting. This data must be strictly separate from training data; otherwise, validation results may be artificially inflated, giving false confidence.
3. Test Data
Test data serves as a final internal check before deployment to production. This dataset simulates real-world use and ensures that the model performs as expected in new scenarios. It acts as an ‘internal pilot test’ to catch issues that weren’t apparent during training or validation.
4. Operational (Result) Data
Once deployed, AI systems generate result data — predictions, classifications, decisions, and inferred outputs. While not a training dataset, this data is highly valuable for monitoring performance over time and for retraining or upgrading the model later. Properly curating and versioning this output can significantly improve continuous learning and model reliability.
The Importance of Proper Data Splitting
Splitting your dataset into training, validation, and test sets isn’t just a technical exercise — it’s a critical foundation for trustworthy AI performance.
1. Common Split Ratios
Typical splits include:
- Training: 70–80%
- Validation: 10–20%
- Test: 10–20%
For example, a 70/20/10 split is common in classification and NLP tasks, ensuring enough training data while giving reasonable room for validation and evaluation.
If the same samples are used for both training and testing, you cannot objectively measure performance. The model may simply “memorize” instead of learning generalizable patterns. This leads to poor performance in real environments.
2. Practical Splitting Considerations
When splitting data:
- Use stratified sampling for imbalanced datasets (e.g., rare disease detection) so that each class is proportionally represented in every subset.
- For time-series data, avoid random splits — use chronological splits while checking for seasonality or trends that might bias results.
- Ensure that all splits are representative of actual use patterns to minimize performance degradation after deployment.
3. Managing Real-World Challenges in Data Splitting
Practical data splitting involves more than percentages. Consider these scenarios:
1) Time-Series Data
For financial forecasting, fraud detection, or sensor analytics, time order matters. Random splits may disrupt temporal dependencies and reduce prediction accuracy. In such cases, iterative or rolling time splits can improve reliability by preserving the sequence of events.
2) Document and Text Data
For textual datasets (e.g., support tickets, legal contracts), splitting by document length, content diversity, or topic category can prevent skewed performance — especially when one class dominates the dataset.
Data Quality — The True Pillar of AI Success
Even the most advanced AI model cannot overcome poor data quality. In fact, industry studies consistently show that data quality issues are among the leading causes of failed AI initiatives. Clean, relevant, and well-structured data enables models to learn meaningful patterns, while noisy or inconsistent data undermines accuracy and trust.
High-quality data is accurate, free of duplication, and properly labeled. It reflects the real environment in which the model will operate and avoids systematic biases that could skew predictions. Consistency across datasets also simplifies preprocessing and reduces the risk of hidden errors that surface only after deployment.
Investing in data quality is not a one-time task. Continuous validation, cleansing, and monitoring are necessary to maintain performance as data evolves over time.
Protecting Privacy and Sensitive Data
AI development frequently involves personal or sensitive information, making data protection a central concern. Without clear governance, organizations face not only technical challenges but also serious legal and ethical risks.
Sensitive data should be encrypted, anonymized, or pseudonymized before being used in model training. Data usage must align with user consent, regulatory requirements, and internal compliance policies. When external AI platforms or APIs are involved, contractual safeguards are essential to prevent proprietary data from being reused for unintended purposes.
From an AI governance perspective, responsible data handling is inseparable from sustainable AI adoption. Trust, transparency, and compliance all depend on how data is managed behind the scenes.
AI Data Versioning: Why It Matters
AI systems are not static. Models are retrained, updated, and refined as new data becomes available. Without proper data versioning, it becomes nearly impossible to trace which dataset produced a particular model behavior.
Effective data version management allows organizations to reproduce results, analyze performance changes, and diagnose issues caused by data drift or distribution shifts. It also enables teams to collaborate more effectively by tracking dataset changes without overwriting previous work.
When data versioning is neglected, performance regressions become harder to explain, and operational risks increase. By contrast, structured version control provides the foundation for long-term stability and continuous improvement in AI systems.
Conclusion
Successful AI does not begin with model selection—it begins with disciplined data management. From understanding data types to splitting datasets correctly, protecting sensitive information, and managing data versions, every step contributes to long-term AI success.
Organizations that invest early in data governance and lifecycle management are better positioned to build reliable, ethical, and high-performing AI systems. In the end, the most practical starting point for AI success is simple yet powerful: great AI starts with great data management.