
Introduction
As artificial intelligence becomes a core capability rather than an experimental technology, organizations are asking more strategic questions about how AI should be designed and operated. The discussion is no longer about whether to adopt AI, but about how AI should interact with data in real business environments.
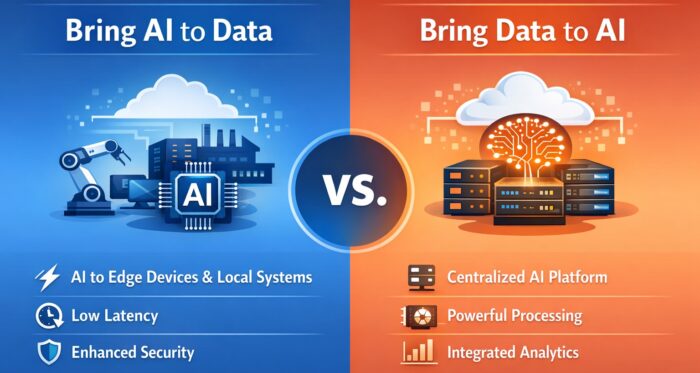
At the center of this discussion are two architectural approaches: Bring Data to AI and Bring AI to Data. These approaches define where AI lives, how data flows, and how organizations balance performance, security, compliance, and operational complexity. Understanding the difference between them is essential for building scalable and sustainable AI systems.
Understanding the Two Foundational AI Data Strategies
AI does not exist in isolation. It depends on data that is often distributed across cloud platforms, on-premises systems, legacy applications, and edge devices. The way organizations connect AI with these data sources fundamentally shapes AI performance and value.
The two dominant strategies differ primarily in one question: Should data move to AI, or should AI move to data? While this may sound like a technical distinction, it has far-reaching implications for cost, governance, latency, and business outcomes.
Bring Data to AI: Centralized Intelligence
Bring Data to AI is the more traditional and widely adopted approach. In this model, data from multiple systems is collected and transferred into a centralized environment where AI models are trained and executed. This environment is typically built on a data lake, data warehouse, or cloud-based AI platform.
By centralizing data, organizations can apply AI at scale. Models can access a broad and consistent view of the business, combining transactional data, behavioral logs, and external data sources. This makes the approach particularly effective for enterprise-wide analytics and predictive use cases.
The main strengths of this approach can be summarized as follows:
- Centralized access to diverse datasets enables richer insights and more accurate models
- High-performance infrastructure such as GPUs can be efficiently shared
- MLOps, governance, and monitoring are easier to standardize
Because data is prepared and validated within a data platform, data quality can also be managed proactively before it is consumed by AI models. This significantly improves model reliability and reproducibility.
However, centralization comes with trade-offs. Moving large volumes of data requires network bandwidth and time, which can increase costs and introduce latency. In regulated industries, transferring sensitive data to a central platform may raise compliance concerns. Additionally, use cases that require immediate responses may struggle with the round-trip delays inherent in centralized processing.
Bring AI to Data: Distributed Intelligence
Bring AI to Data takes the opposite perspective. Instead of moving data into a central AI system, AI models are deployed directly into the environments where data already exists. This includes edge devices, on-premises systems, and data platforms that support embedded AI execution.
This approach is increasingly common in edge AI, on-device AI, and industrial IoT scenarios. By keeping data local, organizations reduce the need for data movement and can perform inference close to the point of data generation.
The key advantages of this model are clear:
- Data remains in place, reducing security and compliance risks
- Inference can happen in real time, enabling immediate decisions
- Network dependency and data transfer costs are minimized
These benefits make Bring AI to Data especially suitable for environments such as manufacturing plants, healthcare facilities, and financial institutions, where latency and data privacy are critical concerns.
That said, distributed AI introduces new operational challenges. Managing model versions across many locations can be complex, and monitoring performance consistently is more difficult than in a centralized setup. Edge environments also tend to have limited computing resources, which restricts model size and complexity. As a result, organizations must invest in lightweight models and robust deployment automation.
How the Two Approaches Differ Across Data, Platform, and Security
From a data perspective, Bring Data to AI emphasizes integration and standardization. Data is cleansed, transformed, and unified before AI consumes it. In contrast, Bring AI to Data focuses on autonomy and locality, allowing each environment to operate independently with its own data.
Platform strategy also differs significantly. Centralized AI architectures benefit from cloud scalability and mature MLOps pipelines, while distributed AI architectures prioritize flexible deployment and execution across heterogeneous environments.
Security and compliance considerations further highlight the contrast. Centralized systems offer strong governance and oversight but increase exposure during data movement. Distributed systems reduce data exposure by keeping data local, but they require careful coordination to enforce consistent security policies across multiple environments.
Practical Implications for Real-World AI Adoption
In practice, organizations rarely choose only one approach. Most real-world AI systems adopt a hybrid architecture that combines both strategies. Model training and long-term analysis often occur in centralized environments, while inference and operational decision-making are pushed closer to where data is generated.
The most important factor in choosing the right balance is not technology, but business intent. Strategic analysis, forecasting, and reporting benefit from centralized intelligence, while operational automation and real-time response demand localized AI. Organizational maturity also matters. Teams early in their AI journey may start with centralized systems and gradually expand toward distributed AI as capabilities mature.
Looking ahead, the future of AI architecture is not about choosing between Bring Data to AI and Bring AI to Data, but about orchestrating both effectively. Central platforms will increasingly serve as governance and learning hubs, while distributed AI will handle real-time execution at the edge.
Advances in federated learning, privacy-preserving AI, and AI agents are accelerating this shift. At the same time, data platforms are evolving into intelligent control layers that manage where and how AI operates across the organization.
Conclusion
Bring Data to AI delivers scale, integration, and analytical depth, while Bring AI to Data provides speed, locality, and trust. Neither approach is universally superior. The real value lies in understanding when and how to apply each one.
Successful AI initiatives are built not on technology alone, but on architectures that respect where data lives and how the business operates. By thoughtfully combining these two approaches, organizations can unlock AI capabilities that are both powerful and sustainable.