
Introduction
When organizations launch AI initiatives, most of the attention naturally goes to model accuracy, algorithm selection, and achieving quick, visible results. These elements feel tangible and measurable, especially during the early phases of experimentation. However, in real-world enterprise environments, the ultimate success or failure of an AI project is rarely determined by how good the model is in isolation. Instead, it is determined by how well the AI system is operated after development.
Many AI initiatives that look promising during analysis or proof-of-concept stages struggle—or fail outright—once they move into production. This is not because the model suddenly stops working, but because operational realities such as data integration, platform scalability, governance, organizational ownership, and cost management were not sufficiently considered upfront. As a result, projects are delayed, operational costs increase unexpectedly, or services are abandoned altogether.
AI delivers its true value only when it is embedded into real services and business processes. This makes questions like “Where will this AI run?”, “How will it be maintained?”, and “Who is responsible for its operation?” far more important than they initially appear. These questions should not be addressed at the end of a project, but rather treated as foundational assumptions from the very beginning. This is precisely why a well-defined AI project operational framework is essential.
The 5 Core Domains of an AI Project Operational Framework
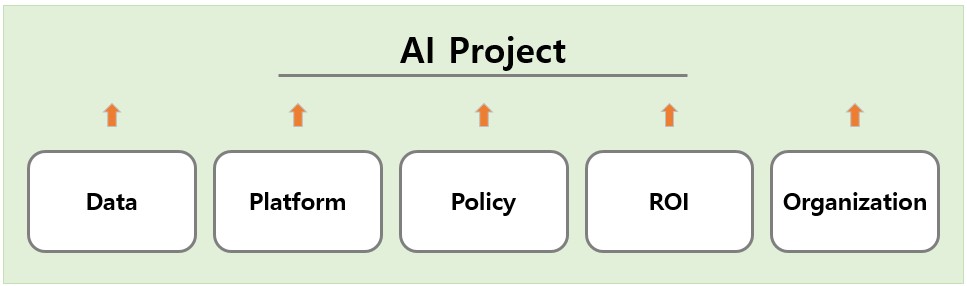
While the exact shape of AI operations may differ depending on industry, company size, and business objectives, successful AI initiatives consistently share five common operational domains: data, platform, policy, performance management (ROI), and organization. These domains do not function independently. Instead, they form an interconnected system where weaknesses in one area inevitably affect the others.
Understanding and designing these five domains together is what separates experimental AI projects from scalable, sustainable AI services.
1. Data: Designing Data Pipelines for Real Operations
Data is almost always the first operational challenge that surfaces after an AI model is deployed. During development, teams typically rely on curated, well-structured datasets prepared specifically for training and testing. In production, however, AI systems must operate on live data flowing directly from source systems, often in real time.
Consider AI services that rely on sensor data such as temperature, humidity, or air quality. In these scenarios, latency matters. Routing data through traditional data warehouses before inference may introduce unacceptable delays. As a result, operational environments often require hybrid data pipelines where batch data and real-time streaming data coexist. Designing for this complexity upfront is critical for stable AI operations.
Another equally important aspect is data storage strategy. Continuously accumulating all operational data may seem harmless at first, but over time it drives up infrastructure costs and can even degrade model performance due to noise and outdated information. A more sustainable approach is to retain only the data required for active operations within production systems, while moving historical or analytical data into separate analytics environments.
Additionally, AI systems frequently generate new data through predictions, recommendations, or automated decisions. If this data is not systematically captured and reintegrated into analytical pipelines, organizations miss valuable opportunities for model improvement and business insight. Operational data design should therefore include feedback loops that allow AI outputs to inform future training and optimization.
2. Scalable and Cost-Efficient Platform Operations
Once data pipelines are in place, the next operational concern is the platform itself. AI workloads are inherently dynamic. User demand fluctuates, models evolve, and computational requirements can change significantly over time. For this reason, infrastructure planning must go beyond static capacity assumptions.
Key considerations include expected concurrent users, monthly active users (MAU), and the computational demands of modern AI models, particularly large language models (LLMs). Cloud-based platforms are often the most practical choice in this context, as they allow organizations to scale resources up or down based on real usage rather than peak theoretical demand. This flexibility plays a crucial role in maintaining cost efficiency while ensuring service reliability.
Front-end architecture also deserves careful attention. Customer-facing AI services typically require tailored interfaces designed for specific user journeys. In contrast, internal enterprise AI initiatives often benefit from a unified front-end that provides access to multiple AI capabilities through a single interface. This approach simplifies maintenance, improves user adoption, and reduces redundant development effort.
No AI platform is complete without comprehensive monitoring. Visibility into user behavior, organizational usage patterns, infrastructure consumption, model performance, and operational costs is essential. These insights not only support daily operations but also serve as the foundation for performance evaluation and strategic decision-making.
3. Policy: From Written Rules to Enforced Systems
AI governance policies are only effective if they function within real systems. Too often, organizations treat policies as static documents rather than operational mechanisms. In practice, AI policies must actively shape how users and systems interact with data and models.
Operational policies should cover areas such as access control, authentication, security, privacy protection, and data usage restrictions. This is especially critical in environments where internal employees and external users access the same AI services. In such cases, clearly defined permission structures directly influence system stability and trustworthiness.
From a regulatory perspective, documented policies are indispensable. They provide clear standards for internal audits and external compliance reviews. However, documentation alone is not enough. Policies must be implemented as enforceable platform features, ensuring that compliance is automatic rather than manual. When governance is embedded into the system itself, organizations reduce risk while increasing operational efficiency.
4. Performance Management: Evaluating AI Through an ROI
AI projects are investments, not experiments that can be left unmeasured. Yet many organizations struggle to evaluate the real business impact of their AI initiatives. Without clear performance metrics, AI operations risk becoming cost centers rather than value drivers.
Effective performance management starts with defining what success actually means for each AI service or project. This typically involves a combination of quantitative indicators, such as cost reduction or revenue impact, and qualitative measures, such as improved decision quality or user satisfaction. Monitoring these indicators over time allows organizations to assess whether AI systems are delivering meaningful returns.
Viewing AI operations through an ROI lens also enables more disciplined decision-making. Projects that consistently underperform can be refined or retired, freeing resources for higher-impact initiatives. This shifts AI from a purely technical endeavor to a strategic business function aligned with broader organizational goals.
5. Organization: Building Teams for Sustainable AI Operations
Organizational design is often the most overlooked aspect of AI operations. While development teams may build AI systems, long-term success depends on who operates and maintains them after deployment.
In many cases, asking development teams to manage ongoing operations is neither scalable nor sustainable. A more effective model separates responsibilities, allowing specialized operational teams to focus on system stability, monitoring, and continuous improvement, while development teams concentrate on innovation and enhancement.
For this transition to succeed, roles and responsibilities must be clearly defined. Knowledge transfer between development and operations teams is particularly important during the early stages of deployment. Temporary collaboration periods help ensure continuity and reduce operational risk. Over time, this structure enables AI services to mature into stable, reliable assets rather than one-off projects.
Conclusion: AI Projects Succeed When Operations Come First
The true completion of an AI project is not the delivery of a trained model, but the establishment of an operational system capable of sustaining value over time. When organizations design AI initiatives with operations in mind from the outset, they dramatically improve their chances of long-term success.
By addressing data, platform, policy, ROI, and organizational readiness early, AI systems can move beyond isolated experiments and become integral parts of everyday business operations. In the end, it is operational excellence—not model sophistication alone—that determines whether AI becomes a lasting competitive advantage.